OpenShift Release Testing
Overview
CI jobs are the backbone of maintaining and improving release quality. The primary purpose of any CI job is to identify regressions early and reliably, preventing issues from impacting customers.
OpenShift employs a multi-layered approach to detect regressions in product quality via release blocking jobs. Each layer is designed to address different stages of the development and release cycle, with trade-offs in detection speed and cost.
We have three primary ways to achieve this: (1) component readiness, (2) payload jobs, and (3) pre-merge testing.
Identifying Which Jobs Qualify for Release Blocking
Candidate jobs for release blocking signal should at a minimum be:
- Useful: is testing a commonly used variation of the product that requires dedicated testing, is testing a project or product that will be widely used on top of OpenShift, or uses OpenShift APIs, or can provide useful feedback via automated testing to OpenShift about whether the project continues to work
- Stable: reached a maturity point where the job is expected to have a stable pattern and is known to “work” (components that are prototypes or still iterating towards an “alpha” would not be blocking)
- Testable: is able to create an install or upgrade job that runs a test suite that can verify the project within a reasonable time period (2-4h) with low flakiness (<1% flake rate)
- Debuggable: uses standard or comparable CI steps for gathering debug data such as must-gather, gather extra, installer log bundles, hypershift dumps, etc.
Good candidates include:
- Jobs that verify upgrade success
- Jobs with a high signal-to-noise ratio (high pass rates)
- Products that will ship on top of OpenShift (layered products)
- Projects or internal tools that depend on OpenShift APIs heavily
- Community projects being evaluated for inclusion into OpenShift or the portfolio
Pre-merge testing
Detecting a regression before it ends up in the release payload at all is the ultimate form of release testing. It is the most expensive form because each change is tested in isolation. Additionally, due to the scope of OpenShift and its configurations, it is not possible to test everything against every individual code change.
We do require you have coverage for both the parallel conformance and serial suites, as well as an upgrade job.
Beyond the minimum jobs, repository owners should make an educated selection of the most impactful jobs that have a high likelihood of detecting a problem. As the team learns, this list should be modified. For example, if a change to the repository causes an incident (see below), the job that was affected should become a presubmit job on that repository.
Typically, presubmit jobs which are present on many repositories that span multiple teams should also be payload blocking.
Payload jobs
Several times per day we produce release payloads that are a roll-up of all the changes that have merged since the previous one. Each payload runs a set of CI jobs – either blocking or informing. Blocking jobs must succeed for the payload to be accepted. Our goal is to achieve an accepted nightly payload every day.
Informing jobs are either on the journey to become blocking by proving their stability over time, or used to provide blocking signal through analysis or component readiness.
Payload blocking jobs are monitored by the technical release team, and regressions to blocking jobs trigger an incident. These jobs must never break. Regressions to these jobs are expected to be detected and reverted within hours. “Fix forward” is not allowed, the identified change must be reverted and reintroduced with payload testing confirming the fix.
Due to the disruptive nature of reverts, good candidates are jobs that have wide impacts if they break – core functionality on key platforms of the product, or jobs that run as presubmits on a diverse set of repositories.
Component readiness
Component Readiness compares historical results against a recent sample and uses various heuristics to ensure a test meets quality bars and never regresses. The primary mechanism is a statistical test called Fisher’s Exact, that has an automatic fallback to the best a test case ever was. For tests without a presence in the historical basis (i.e., new tests), we enforce that they succeed at least 95% of the time.
The goal is simple: ensure each release is as good as or better than the last.
Every test in OpenShift is assigned to a Jira component (e.g. Installer, kube-apiserver, etc) and every job in OpenShift is assigned variants (Platform, Network, Topology, etc). The grid is organized by components on the y-axis, and variants on the x-axis. Each grid coordinate then either has a red or green square; where red indicates that at least one test for that component isn’t meeting the requirements for the view.
There are multiple views available in Component Readiness, and new ones can be
created for particular needs. There is always a “X.Y-main” view that is used to
determine a release’s readiness to ship – this is the primary view, and is where the
highest quality signal resides. Business owners choose which combinations to enforce
regression protection on in the -main views.
Selecting a path
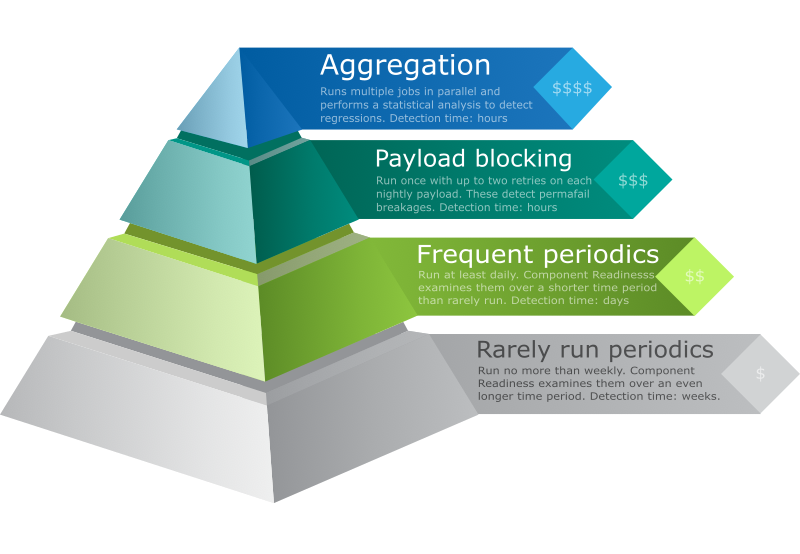
When considering whether payload blocking or component readiness is right for you, the primary concerns are detection speed and cost.
 Pyramid Chart Vectors by Vecteezy
Pyramid Chart Vectors by Vecteezy
| Use Case | Detection Speed | Cost | Mechanism |
|---|---|---|---|
| Must never regress | Hours | $$$$ | Release payload, aggregation |
| Must never break | Hours* | $$$ | Release payload, once with retries |
| Must never regress | ~5 Days | $$ | Component readiness, frequent periodics |
| Must never regress | Weeks | $ | Component readiness, rarely run** |
* Payload blocking allows regressions on a multi-day basis, but can also
be included in component readiness for longer term regression protection if approved by the business.
** Rarely run is currently a work in progress, and will be an option at a future date
Process for creating a new job
Create a new multi-stage job on top of latest OCP that runs as a periodic job.
Periodic jobs must:
- follow the naming guidelines
- be attached to release branch (release-X.Y) - do not add periodics to your main or master branch unless unavoidable, and if done utilize the variants feature of ci-operator to group like releases
- be kept separate from any presubmits by using the variants feature of ci-operator
- use the release payload provided by CI in the
RELEASE_IMAGE_LATESTandRELEASE_IMAGE_INITIALenvironment variables; do not hard code any particular release image - re-use as much of the existing step registry as possible
- include standard
gather,gather-extra, and resource watch steps, or in rare cases custom steps that gather as much of the same data as possible
You should initially run the job on a frequent basis to get a good sample to determine its reliability; at least daily. Frequency can be adjusted later depending on the path for release blocking you choose. Job pass rates can be monitored in Sippy.
Some jobs may only need to run weekly when there’s little platform deviation, and there’s already at least one frequently run job. For runc for instance, we want to run most jobs as weekly because there’s one platform that runs daily. We can use rarely run and longer term comparisons to detect unlikely platform-specific regressions.
Where possible you should be running this same test on PRs to your project’s repos to make sure changes to your project don’t result in downstream breakages to the release job. We recognize this may not be an option for all projects.
Becoming Blocking in Component Readiness
Before you can be included in the X.Y-main view, you must prove your job is stable
for a release. Even then, inclusion in the main view is more of a business
decision than an algorithmic one. Approval is ultimately in the hands of OCP’s
business owners or their delegate (such as an OCP architect).
To prove stability, update the component readiness views to include your job’s
unique variants in the candidate view. If there’s no candidate view for that
release yet, create one (e.g. 4.19-candidate). You may also create custom views
as needed, such as those that do cross-variant comparisons. For new platforms,
topologies, etc, doing cross-variant comparisons with existing blocking jobs is a good
strategy to not only ensure your jobs don’t regress, but that they are as good as others.
Monitor the view(s) for the duration of the release, and ensure that all squares are
green prior to that release shipping. After one release of proving your job is stable
enough and regressions can be fixed, you may open a PR to include it in the X.Y-main
view for the following release. This should be done no later than a month after
branching for the release occurs. This PR must be approved by the business owner, or
their delegate (such as OCP architects).
Becoming Payload Blocking
Our goal of weekly z-stream releases necessitates that payload blocking jobs provide stable and unambiguous signal about regressions in the product or the projects and projects on top. To provide this level of stability and observability, any new payload blocking jobs must follow the below steps.
Note: these jobs’ data also feed into component readiness.
Become informing
After at least one sprint of running the job, and success rate is at least 70%, the job will be considered stable enough to be considered for inclusion to the nightly informing jobs. Informing jobs should be a stepping stone to providing payload blocking signal, if your goal doesn’t require to be directly blocking on payloads, consider cron-scheduled periodics instead and monitored via Component Readiness.
To become an informing job, file a ticket in the TRT Jira project, containing:
- The names of the jobs to become informing
- Justification for payload blocking over component readiness
- Links to the job history in Sippy showing its historical pass rate
- A channel to send Slack alerts, and the threshold to alert on (minimum of 70%)
- A method for escalation of breakages to the team (jira, slack, e-mail, etc)
- A manager backstop to contact if the job fails for a prolonged period
Jobs that fail for an extended period of time without an expectation of return to stability within a reasonable timeframe (~1 sprint), should be evaluated for removal as an informing job. Jobs that have remained informing for 2 releases without going blocking should be removed from informing status (but may continue to run as scheduled periodics).
Extract blocking signal
An optional step along the way to become blocking would be to extract partial blocking signal from informing jobs using blocking analysis jobs.
We are able to analyze a set of informers matching specific criteria, and ensure that a particular
part of the job passes. We have two of them today, install-analysis-all and overall-analysis-all. Install analysis
ensures that we get at least one successful install across groups of jobs. For example, we can ensure we get at least one
good install across each platform, each CNI, each IP stack, etc. overall-analysis-all ensures that the test step succeeds,
effectively acting as a proxy for “the job passes entirely.” For example, we require that techpreview jobs pass all serial
and parallel conformance tests at least once on any platform.
Becoming Blocking
After at least 2 sprints of informing status, you may request the job become blocking by again filing a ticket in the TRT Jira project.
Blocking jobs come with the responsibility of being responsive to breakages. Generally, TRT expects a team that requests a blocking job to respond to a breakage within 4 hours during their normal working hours only. In exchange for this agreement, TRT will monitor the jobs, alert on them, and revert changes in the product that caused the breakage.
Once with retries, or aggregated?
There are two options for payload blocking jobs: aggregated, and once with retries. Aggregated jobs give us must never regress functionality. By running a series of jobs in parallel, we can do a statistical analysis of the results and not only determine if a test or job is permanently broken, but also if there was a more subtle regression – i.e. a test dropped from 99% pass rate to 85%.
We largely expect the set of aggregated jobs to be fixed to where it is now – core platform upgrades – and to shift most regression detection to Component Readiness. New aggregated jobs would be an exception unlikely to be granted.
Most payload blocking jobs should be single run with an optional amount of retries (up to 2 retries for a total of 3 runs). This allows us to detect near permanent breakages.
Shortcuts To Becoming Informing or Blocking
Above we request at least 9 weeks from the time a job is created to the time it could first become blocking. This is to help make sure the job is stable enough and will not swamp TRT or unreasonably prevent us from getting green payloads.
However, in some scenarios, it may be possible to shortcut this process. We have recently gained the ability to run specific jobs an arbitrary number of times via Gangway. This allows us to accumulate more data in a shorter window of time, and see if a job is stable enough to go blocking. If you feel this is necessary, please get in touch with TRT and we can try to work out budget concerns and amount of data runs required.